2020 metų spalį Registrų centras paskelbė atvirą Lietuvos adresų kadastro duomenų rinkinį. Šiame duomenų rinkinyje yra informacija:
- Adresų taškų (taško koordinatės, miestas, gatvė, namo numeris, korpusas)
- Gatvių ašinių linijų (linijos geometrija, gatvės pavadinimas)
- Administracinių ribų (gyvenviečių ribų poligonas, gyvenvietės pavadinimas)
Kadangi rinkinys atviras, nors ir neatnaujinamas, buvo nuspręsta jį įkelti į OpenStreetMap duombazę. Visą rinkinį, išskyrus Vilniaus duomenis, nes Vilniaus miesto savivaldybė jau daug metų kas savaitę atnaujina atvirą adresų rinkinį, todėl Vilniaus adresų informacija jau buvo tvarkinga ir Vilniaus miesto savivaldybės informacija yra naujesnė.
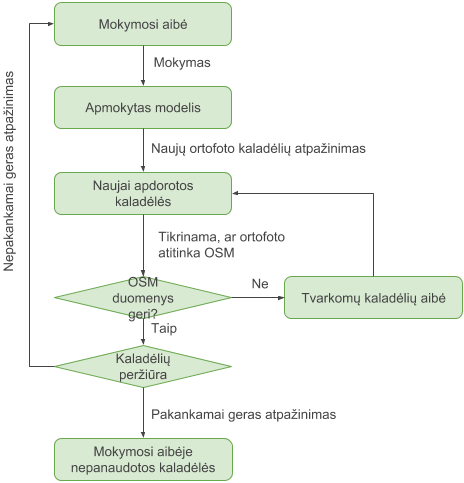
Buvo paruošta programinė įranga, leidžianti importuoti adresų duomenis atsižvelgiant į jau esamus duomenis:
- neimportuoti jau esamų adresų
- jei yra pastatas, kuriam galima vienareikšmiškai priskirti adresą, tai adresas priskiriamas pastatui
- jei naujo adreso vietoje nėra nei pastato, nei kitų adresų, adresas importuojamas kaip naujas taškas
- kitais atvejais paruošiamas pusiau-automatinis adreso įkėlimas, t.y. žmogus peržiūri vietą ir padaro sprendimą, kaip/kur pridėti adresą
- pašalinti perteklinius adresus
Adresų importo progresą galima matyti šiame video:
Įkėlimas užtruko virš penkių mėnesių, nes adresai (kaip ir bet kokia kita informacija) nėra izoliuoti – jie susiję su kitais duomenimis. Pavyzdžiui gatvėmis (jei yra gatvės A adresas, tai tokia gatvė privalo būti netoli adreso) ar gyvenviečių ribomis (jei yra gyvenvietės B adresas, tai jis privalo būti tokios gyvenvietės ribose).
Kaip paaiškėjo, būtent gatvių informacijos sutvarkymas ir buvo daugiausia žmogiškų pastangų reikalaujanti dalis, nes gatvių duomenų nebuvo galima įkelti automatiškai – algoritmas būtų stipriai per sudėtingas (kelius reikia kurti, jungti, skaidyti, keisti klasifikacijas ir pan.), na ir kai kurių gatvių geometrijos informacija OpenStreetMap duombazėje yra gerokai tikslesnė, tai vietomis tik žmogus gali nuspręsti, kuriam keliui priskirti pavadinimą ar kokia turėtų būti gatvės geometrija (pvz. kad nekirstų pastatų ar vandens telkinių).
Gatvių pildymui buvo sukurtos ataskaitos, leidžiančios gatvių pavadinimų tvarkytojams matyti nesutvarkytas gatves išrikiuotas pagal atstumą nuo jų pageidaujamo taško: buvo tvarkoma nuo Vilniaus, Klaipėdos, Kauno, Biržų ir Šiaulių. Kaip sekėsi tvarkyti gatvių pavadinimus galima matyti šiame video:
Viso šio projekto rezultatas – užpildyta/atnaujinta Lietuvos adresų informacija, sutvarkyti gatvių pavadinimai. Adresų skaičius Lietuvoje pašoko nuo 300 tūkstančių iki 1,1 milijono! Buvo sutvarkyta daugiau nei 25 tūkstančių kelių pavadinimų informacija: įvestas pavadinimas arba pridėta žyma, kad kelias patikrintas ir jis neturi pavadinimo.
Adresai nėra statinis dalykas, jie pastoviai keičiasi. Kol nesutvarkyta situacija su Registro centro veiklos nuostatais (šitą dalyką valdo Lietuvos Respublikos Seimas), tol adresų informacijos atnaujinimų tikriausiai arba negausime, arba gausime labai periodiškai, taigi adresų atnaujinimas lieka mūsų – žymėtojų – užduotis. Na o kai adresų kadastro duomenys bus galutinai atverti – mes jau būsime pasiruošę jį daug greičiau integruoti.