Ankstesniame įraše buvo rašyta apie mašininio mokymosi reikalavimus ir potencialą atpažįstant objektus ortofotografiniuose žemėlapiuose. Šį kartą parašysiu apie tai, kokie stebimi praktiniai rezultatai su Lietuvos objektų atpažinimu.
Pastatų atpažinimas
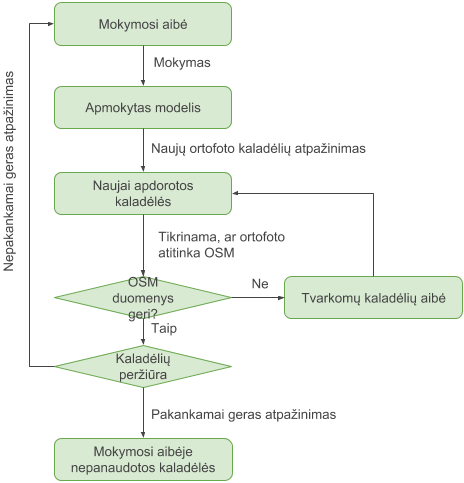
Pastatų atpažinimas bandomas jau du mėnesius. Modelis apmokytas su beveik tūkstančiu kaladėlių. Tai nėra didelis kiekis, bet jau matomi šiokie tokie rezultatai ir tendencijos. Verta paminėti, kad pradžioje pabandžius mokyti su tiesiog iš OpenStreetMap paimtais duomenimis, rezultatai buvo daug prastesni, nei kruopščiai parinkus (ir dažnai pataisius) OSM duomenis. T.y. žemiau pateikiami rezultatai modelio, kuris apmokytas su tiksliai (kiek tai įmanoma) pažymėtais pastatais – iki minimumo sumažintas klaidingų ar netikslių etikečių skaičius.
Mokymo rinkiniui kurti ir rezultatams tikrinti buvo sukurta paprasta web aplikacija, apie kurią parašysiu trečiame įraše. Kol kas užteks tik bendros informacijos. Apmokytam modeliui buvo pateikta dvidešimt tūkstančių kaladėlių, kuriose jis turėjo ieškoti pastatų. Štai pavyzdinis rezultatas:

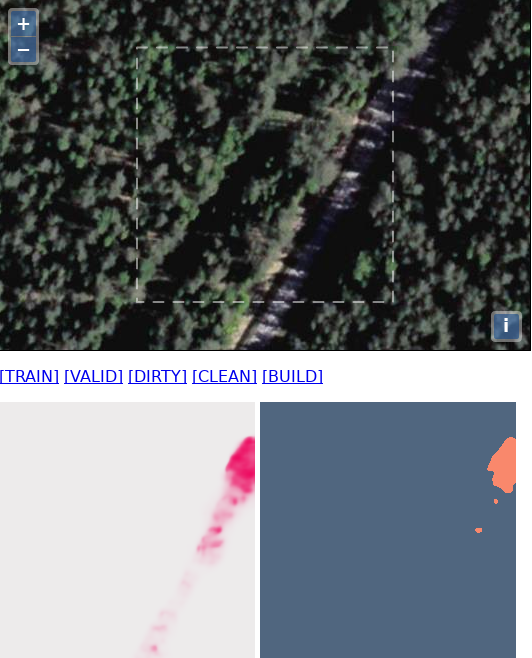
Viršutinėje dalyje matome ortofoto kaladėlę (apibrėžtą punktyrais), kurioje ieškoma pastatų. Žaliai pažymėti OpenStreetMap jau pažymėti pastatai (šios informacijos robotas atpažinimo metu neturi).
Po ortofotografija yra dvi kaladėlės – roboto darbo rezultatai. Kairėje pusėje esančioje kaladėlėje yra nuotraukos segmentacijos rezultatas: kiekvienam taškui paskaičiuota tikimybė, kad jame yra pastatas. Kuo taškas rausvesnis, tuo didesnė tikimybė, kuo baltesnis – tuo mažesnė. Dešinėje kaladėlėje yra išrinkti tik taškai, su didele pastato buvimo tikimybe – tai yra šio etapo galutinis rezultatas. Kaip matome, atpažinti pastatai yra apvalūs. Tai pasekmė to, kad modelis pastato kraštus atpažįsta su vidutine tikimybe. Norint tokius duomenis naudoti automatiniam geometrijos (pastato formos) identifikavimui, reikėtų pritaikyti papildomą algoritmą, kuris iš tokio „apvalaus“ daikto sukurtų „kampuotą“ pastatą. Tai yra netrivialu, o gal net ir neįmanoma, kol turime dabartinę atpažinimo kokybę.
Kaip ten bebūtų, pirmam tikslui – trūkstamų pastatų identifikavimui ir nebeegzistuojančių pastatų aptikimui – šito pilnai užtenka. Pavyzdžiui, patikrinęs ~20000 kaladėlių aplink Labanorą, robotas iš karto galėjo atmesti ~95% kaladėlių, kur jis nerado jokių pastatų. Taigi net rankiniu būdu peržiūrint rezultatus, sutaupoma ~95% laiko, nes nebereikia tikrinti kaladėlių, kuriose yra tik miškai, vanduo, pievos, pelkės ar keliai.
Aukščiau pateiktoje nuotraukoje matome, kad robotas visgi nerado pietvakariuose nuo viršutinio pastato esančio pastato (tiksliau rado nepakankamai užtikrintai). Ir tas trūkstamas pastatas turėjo tikimybę panašią į automobilį, stovintį greta apatinio aptikto pastato. Taigi „false negative“ problema yra, tiesa, lyg ir nedidelė. Esant tokiai situacijai kaladėlė įtraukiama į mokymosi aibę, kad per kitą mokymąsi robotas išmoktų aptikti tokį pastatą (ir neaptikti automobilio).
Yra ir „false positive“:
Čia matome, kad robotas neteisingai kaip pastatą identifikavo kai kurias kelio atkarpas, arba tiltą:

Taip pat problemų kol kas kyla ir su kai kuriais objektais ant žemės (polietileninė plėvelė ant lysvių(?) kaladėlės viduryje:

Kadangi robotas nepavargsta, jam neatsibosta, neišblėsta dėmesys, o ir kontrastas jam mažiau svarbus, jis be problemų randa pastatus, kuriuos žiūrint akimis galima ir praleisti:

Taigi rezultatai geri, atsižvelgiant į pirmą tikslą: aptikti trūkstamus ir nebeegzistuojančius objektus. Tikiuosi, kad neteisingi aptikimai beveik dings dar geriau apmokius modelį.
Modelio apmokymas
Peržiūrint rezultatus atrenkamos kaladėlės mokymuisi. Tai ir „positive“ kaladėlės – su įvairių formų, spalvų pastatais, ir „hard negative“ kaladėlės – kuriose pastatų nėra, bet modelis juos ten aptinka. Į mokymosi aibę neįtraukiamos kaladėlės, kur pastato matosi tik kampas, arba kur aš pats negaliu pasakyti, kokia yra pastato tiksli geometrija arba apskritai, ar yra pastatas ortofotografijoje.
Pats apmokymas turėtų būti daromas naudojant GPU (Grafinius procesorius), bet, kadangi tokio neturiu, kol kas mokau naudodamas paprastą CPU. Dėl GPU nenaudojimo apmokymas yra ~10 kartų lėtesnis, tai su ~1000 mokymosi kaladėlių ir 15 epochų modelis mokėsi apie savaitę. Ateity reikės galvoti kažką gudresnio.
Geometrijos aptikimas
Dabartinis aptikimo rezultatas neleidžia pakankamai tikslai identifikuoti pastatų geometrijos. Paklaida tiesiog per didelė (pabandykite nežiūrėdami į ortofotografiją, vien iš tikimybinių paveiksliukų identifikuoti, koks turėtų būti pastatas, t.y. kur ir kokie turėtų būti pastato kampai). Su kiekvienu nauju mokymusi su didesniu kaladėlių skaičiumi, tikimybinis pastato šablonas tikslėja, bet klausimas, kiek jis tikslės. Gali būti, kad tiesiog ORT10LT nuotraukos yra nepakankamai detalios. Tarkime čia naudojamos 18 mastelio nuotraukos, o kolegos užsienyje gali džiaugtis 19 mastelio ortofotografijomis. Taigi dar reikia mokytis ir žiūrėti, kas gausis.
Turint tikslesnius šablonus reikės rašyti algoritmą vektorinės pastato geometrijos kūrimui iš rastro (jei niekas kitas tokio algoritmo neparašys). Minčių, kaip tą padaryti galima rasti Microsofto pristatyme.
Kol kas tiek. Kitame įraše papasakosiu, koks sukurtas robosato „apvalkalas“ patogesniam mokymo aibės kaupimui ir rezultatų naudojimui.