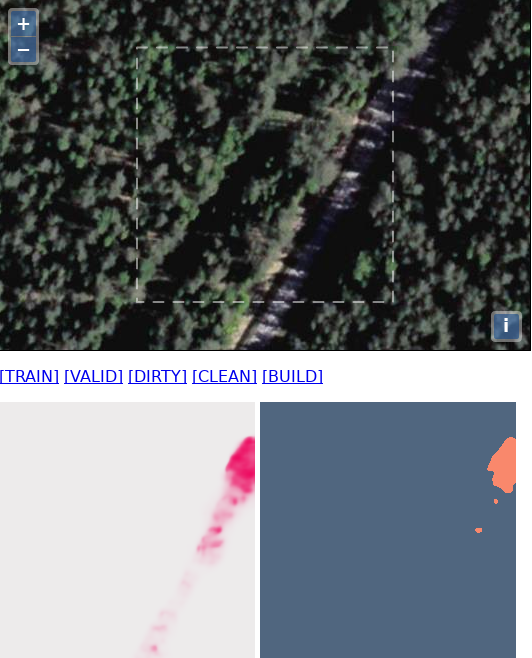
Prieš kelias savaites rašiau, kokią naudą gali duoti mašininis mokymasis OpenStreetMap duomenų tvarkymui Lietuvoje, taip pat kokie yra pirmų praktinių bandymų rezultatai.
Kaip ir daugeliu atveju, plikas kodas neduoda žymios naudos, jei jis nėra integruotas į didesnį procesą, tai šį kartą aprašysiu, koks kol kas sugalvotas mašininio mokymosi panaudojimo procesas Lietuvoje (džiugu būtų išgirsti ir jūsų minčių!).
Mašininio mokymosi veikimui mums reikia sukurti kokybišką mokymosi duomenų aibę, o tada ją palaikyti, nes su laiku keičiasi tiek ortofoto, tiek ir OSM duomenys. Todėl reikia periodiškai pažiūrėti, ar mokymosi kaladėlėse OSM duomenys vis dar atitinka ortofoto. Jei to nepadarysime, vykdant naujus modelio mokymus, jis gali mokytis pagal neteisingus duomenis, todėl rezultatų kokybė gali kristi.
Nesinori į mokymosi aibę dėti labai panašių kvadratų, arba tokių, kuriuose atpažinimas jau vyksta gerai. T.y. šiuo metu manau, kad geresnę mokymosi aibės kokybę galima pasiekti rankiniu būdu peržiūrint atpažinimo rezultatus ir tada į mokymosi aibę pridedant tuos kvadratus, kuriuose dar reikėtų papildomai pasimokyti: t.y. tiek atpažinti nepastebėtus pastatus, tiek ir neatpažinti kaip pastatų visai kitų objektų.
Gauname tokį procesą:
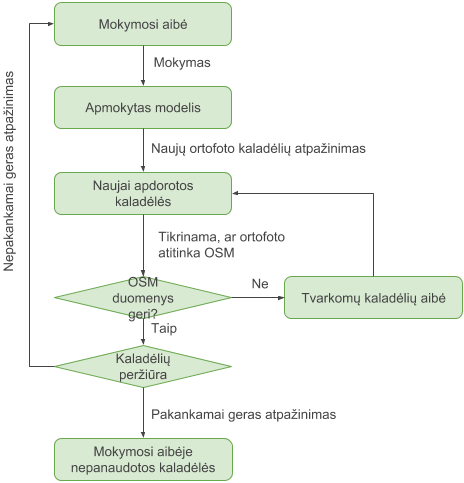
Viso ko pradžia yra pradinė mokymosi aibė. Pačioje pradžioje nėra kito kelio kaip tik rankiniu būdu parinkti šiek tiek kaladėlių, kuriose būtų analizuojami objektai (pvz. pastatai). Kol pradinė mokymosi aibė bus nedidelė (keli šimtai įrašų), modelis dar nepateiks gerų atpažinimo rezultatų, bet pradėti nuo kažko reikia.
Apmokę modelį su pradiniu duomenų rinkiniu, galime paprašyti, kad modelis patyrinėtų didesnį plotą (dar nematytą mokymo metu, tarkim 10000 ortofoto kaladėlių). Peržiūrint rezultatus, visų pirma patikriname, ar ortofoto atitinka OSM duomenis (peržiūrimos tik tos kaladėlės, kuriose modelis aptiko mums rūpimų objektų, arba kaladėlės, kuriose modelis objektų neaptiko, bet OSM tokie objektai yra pažymėti). Jei OSM duomenys nėra pakankamai geri, tai kaladėlė perkeliama į „purvinų“ kaladėlių sąrašą. Šį sąrašą gali peržiūrinėti kiti žmonės, kurie užsiima OSM duomenų tvarkymu. Patvarkius duomenis, kaladėlė vėl iš naujo patenka į peržiūrą, kur teoriškai ji gali pakartotinai būti nusiųsta į „purvinų“ kaladėlių aibę.
Jei kaladėlė „švari“, t.y. ortofoto duomenys sutampa su OSM duomenimis, tada daromas sprendimas, ar kaladėlę tiesiog pažymėti kaip sutvarkytą, ar ją įtraukti į mokymosi aibę. Sprendimas daromas remiantis tokiu kriterijumi: „ar mokymosi aibė turės naudos iš šios kaladėlės?“. Naudos gali turėti, kai:
- Kaladėlėje buvo objektas, kurio modelis neatpažino, arba atpažino labai netiksliai. Reikia atsižvelgti ir į ortofotografijos kokybę: jei modelis objektą atpažino nepilnai, bet likusios dalies nesimato (tarkim už medžių), reikia pagalvoti, ar tikrai galima vienareikšmiškai pasakyti, kokia yra nematoma objekto geometrijos dalis. Mes nenorime modeliui pateikti savo spėjimų ir paprašyti pagal juos mokytis.
- Kaladėlėje nėra objekto, o modelis jį rado. Paprastai tai būna koks nors kitas objektas, kuris kažkuo panašus į mums rūpimą objektą. Pavyzdžiui tiltas gali pasirodyti panašus į pastatą, kūdrą gali būti sunku atskirti nuo kitų vandens objektų – upių, ežerų ar tvenkinių. Arba pastatai ir šiltnamiai – kol kas negaliu pasakyti, ar geriau šiltnamius atpažinti kartu su pastatais, ar geriau juos atskirti.
Toks procesas leidžia didelį darbo kiekį skaidyti į mažus gabaliukus, kas padeda darbo atlikimui bei progreso sekimui. Taip pat mašininio mokymosi dalis atskirta nuo duomenų redagavimo dalies. Taigi žmonės, kurie moka redaguoti duomenis, nebūtinai turi būti mokomi mašininio mokymosi specifikos. Tuo pačiu mašininio mokymosi užduotį atliekantiems nebūtina mokytis duomenų redagavimo.
Ateities planuose yra du esminiai darbai:
- automatizuti modelių rezultatų ir OSM duomenų palyginimo užduotį, t.y. automatiškai nustatyti, ar objektų trūksta, yra per daug, o gal pasikeitė objektų geometrija;
- automatizuoti objektų geometrijos nustatymą pagal modelio rezultatus.
Taigi bendras principas toks. Dabar laukia netrivialūs automatizavimo uždaviniai.